


Não parece, mas o Canva acabou de completar dez anos: a empresa australiana foi fundada em primeiro de janeiro de 2013. A plataforma online de design gráfico começou de forma descompromissada, atingindo pouco menos de 750 mil usuários em seu primeiro ano, mas foi gradativamente conquistando seu espaço, até a atingir a marca atual de mais de 100 milhões de usuários ativos no mundo todo. Com a aquisição do Pexels e do Pixabay, ambos em 2019, o Canva passou a oferecer cerca de 100 milhões de fotos e elementos gráficos, além de 50 milhões de novas mídias que os próprios usuários sobem para a nuvem diariamente.
Todos esses números exigem um banco de dados robusto e um crescimento tão agressivo em apenas uma década exigiu um escalonamento do armazenamento de arquivos que não comprometesse as operações diárias. No final de novembro de 2022, o time de engenharia do próprio Canva dissecou como funcionava sua estrutura interna e como foi realizado o escalonamento nos bastidores.
Microsserviços e MySQL
O Canva foi construído a partir de uma arquitetura de microsserviços, orientado a recursos. Cada serviço disponível internamente oferecia uma API, tinha persistência isolada e era controlado por um time reduzido de engenheiros.
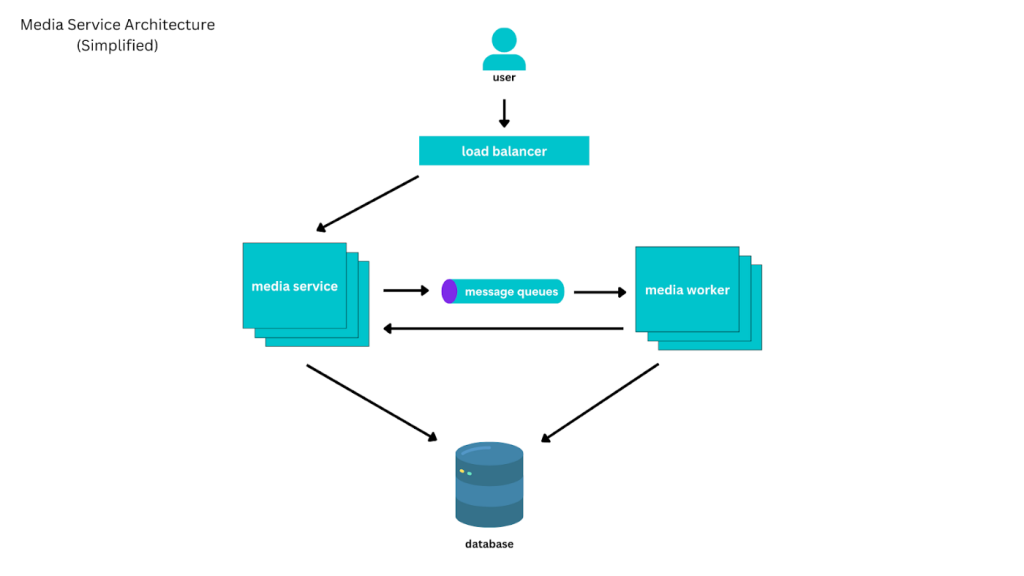
Entretanto, dada suas intenções e complexidade, o Canva passa armazenar um volume considerável de informações. Cada mídia disponível na plataforma precisa conter os seguintes dados associados:
- Sua identificação.
- O usuário proprietário.
- Se faz parte da biblioteca de mídia do Canva.
- Informação de fonte externa.
- Seu status (ativo, descartado ou exclusão pendente).
- Um amplo conjunto de metadados sobre seu conteúdo, incluindo título, artista, palavras-chave e informações sobre cores.
- Uma referência aos arquivos da mídia e onde eles estão armazenados.
A arquitetura original do Canva permaneceu a mesma por anos: os microsserviços eram camadas finas em torno do MySQL hospedados em clusters AWS RDS. Quando havia necessidade de se escalar as operações, havia um crescimento vertical com instâncias maiores. Posteriormente, foi empregado o crescimento horizontal, com réplicas de leitura do MySQL.
Entretanto, o Canva cresceu muito além das expectativas e os problemas começaram a aparecer…
Problemas e soluções
Na infraestrutura original, mudanças de schemas em tabelas de mídia muito grandes poderiam levar um tempo excessivo. Com o inchaço do banco de dados, operações DDL no MySQL provocavam uma grande degradação de desempenho. A situação estava tão grave que não era mais possível executar esse tipo de operação ao mesmo tempo em que se atendia ao tráfego do usuário, havia um risco real de impactar a disponibilidade de todo o serviço.
A primeira saída encontrada pelo time de engenharia do Canva estava focada em “apagar o incêndio”: o uso do projeto gh-ost, uma ferramenta de código aberto para migração de schemas em MySQL. O nome da solução deriva do fato de ser criada uma tabela “fantasma” (“ghost”, em inglês) similar à tabela original. Através do gh-ost, migra-se essa tabela vazia, é realizada uma cópia lenta e incremental dos dados da tabela original, ao mesmo em que se propagam alterações contínuas para a tabela fantasma. Completado o processo, no momento certo, é realizada a substituição da tabela original pela tabela fantasma.
Infelizmente, o volume das tabelas do Canva atingiu um ponto em que outros problemas e limitações surgiram, que não podiam ser simplesmente solucionadas com utilitários melhores. Mesmo com o uso do gh-ost, uma migração de schema poderia levar seis semanas para ser concluída, atrasando o desenvolvimento de funcionalidades. O limite do tamanho dos volumes no Elastic Block Store da AWS também estava sendo alcançado (16TB!). Cada instância de RDS, por sua vez, apresentava um limite de 2TB, por ter sido criado através de um snapshot de um sistema de arquivos ext3. Mesmo assim, cada aumento de volume implicava em um aumento de latência significativo na experiência do usuário.
Em 2017, o Canva estava próximo da marca de um bilhão de arquivos de mídia. Seria impossível continuar com a arquitetura anterior: “começamos a investigar caminhos de migração, com forte preferência por abordagens incrementais que nos permitissem continuar a escalar e não colocar todas as nossas apostas em uma única escolha de tecnologia não comprovada”.
Entretanto, mais uma vez, foi necessário adotar medidas de emergência para estender a viabilidade da estrutura existente. Desta forma, os metadados de conteúdo de mídia foram migrados em uma coluna JSON, com seu próprio schema, gerenciado pelo próprio serviço de mídia. O conteúdo repetido foi removido (como, por exemplo, nomes de bucket s3) ou codificado em uma representação mais curta.
Restrições de chave estrangeira foram removidas. Além dessas medidas, foi adotado um sistema simples de sharding, que melhorou a performance para os usuários. Essa arquitetura provisória atendia as solicitações mais requisitadas.
Enquanto parte do time utilizava de paliativos para manter o Canva operando no limite da performance, o restante da equipe de engenharia de software realizava testes e avaliava alternativas em busca da melhor solução definitiva. O resultado atendia pelo nome de DynamoDB.
Quem sabe faz ao vivo
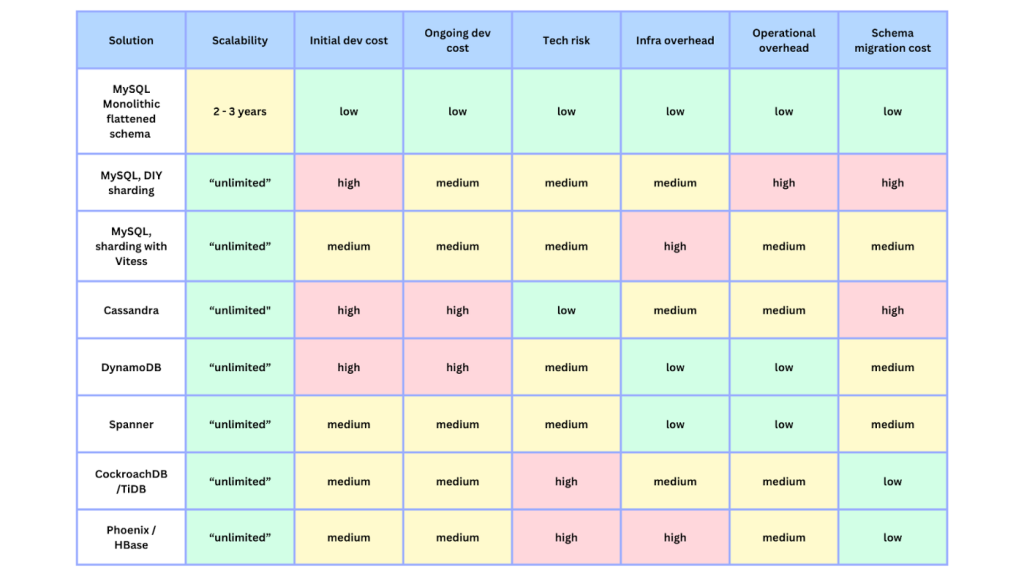
A tabela a seguir mostra não apenas a grande quantidade de soluções que foram estudadas, como também os critérios adotados para fazer uma escolha que atendesse às necessidades da plataforma:
Escolhido o DynamoDB, o desafio seguinte foi realizar uma migração que não impactasse os usuários e que não produzisse nenhuma queda de serviço. Era necessário migrar em produção, ao vivo.
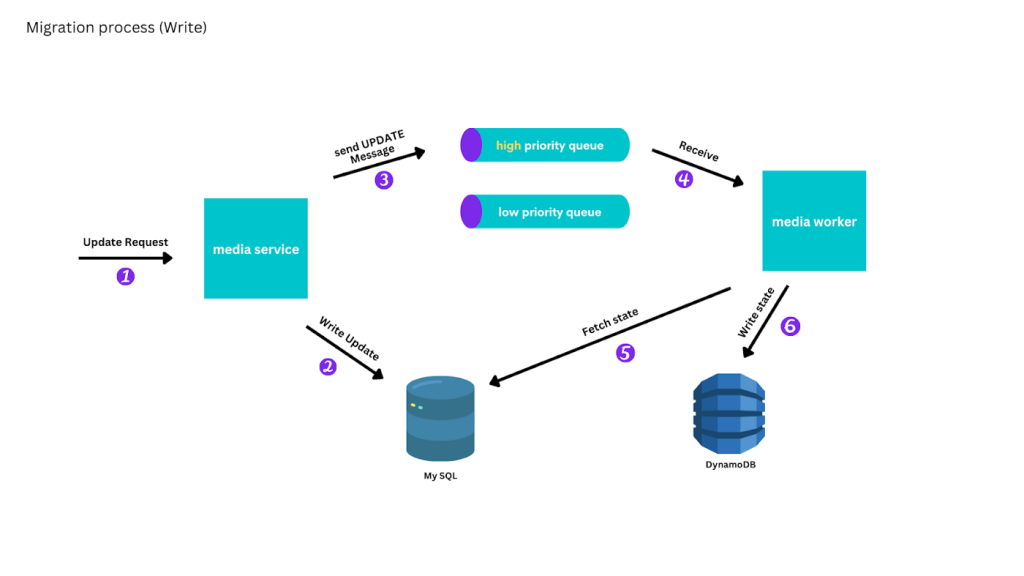
Assim, operações de escrita e atualização ganharam prioridade durante a replicação. Havia duas filas de operações, uma com alta prioridade que alterava o conteúdo dos bancos, enquanto operações de consulta e leitura iam para a fila de baixa prioridade. Os instanciadores precisavam zerar as instruções da fila de alta prioridade antes de processar a segunda fila.
E mesmo as operações de consulta receberam um tratamento diferenciado. Antes de passar a servir todas as consultas exclusivamente pelo DynamoDB, foi montado um esquema de paralelismo, com leitura dupla no DynamoDB e no MySQL, com comparação para confirmar a eficiência do processo de replicação. Na medida em que as falhas de replicação foram sendo corrigidas, o sistema foi mudando para um regime preferencial, em que os resultados do DynamoDB eram majoritários, ainda que com mecanismos de uso do MySQL para dados que não tinham sido replicados.
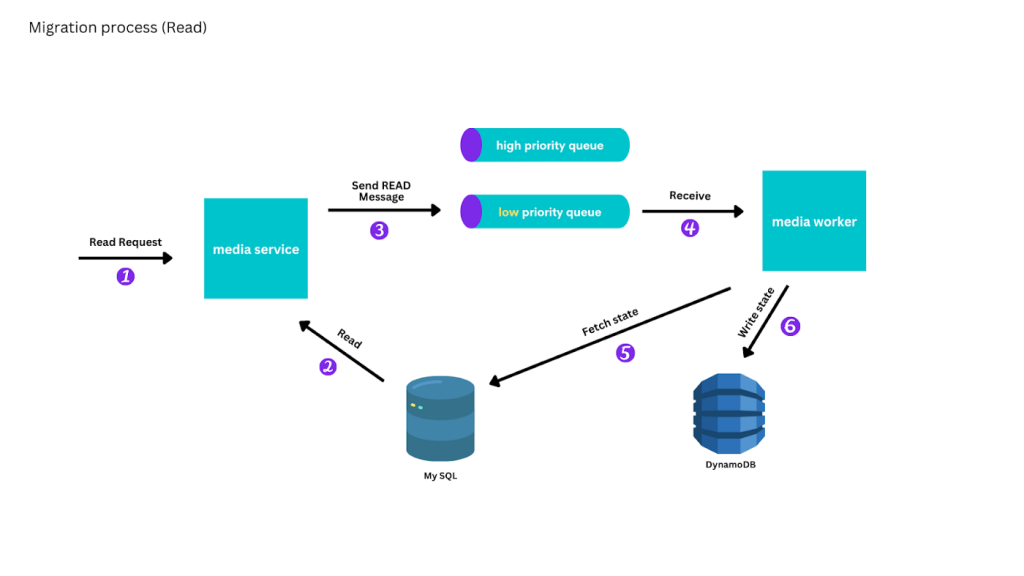
A conclusão do processo foi através de um escaneamento final. Essa varredura passou obrigatoriamente por todas as mídias, começando pela mais recente criada, e colocou uma mensagem na fila de baixa prioridade para replicar a mídia para o DynamoDB. A equipe de engenharia do Canva determinou que o processo de sincronização só avançasse enquanto a fila de baixa prioridade estivesse aproximadamente vazia.
Certos de que os bancos estavam sincronizados, faltava “queimar a ponte”, ou seja, transferir de vez todas as operações de escrita para o DynamoDB e dizer “adeus” ao MySQL, o que envolvia mudanças no código dos serviços. Para minimizar riscos, a equipe de desenvolvimento migrou primeiro os testes de integração existentes para testar a mídia migrada e a mídia criada diretamente no DynamoDB. Depois disso, foi migrado o restante dos testes de integração para executar na implementação do serviço DynamoDB e foi realizado todo um novo conjunto de testes de ponta a ponta.
Em caso de problemas, havia um guia de procedimentos que permitiria alternar as consultas de volta para o MySQL em segundos, se necessário. Obviamente, o próprio guia de procedimentos foi alvo de ensaios constantes enquanto era implementada a mudança de ambientes.
Lições aprendidas com a migração
Segundo a postagem publicada pelo time de engenharia do Canva, foram aprendidas pelo menos três lições com todo o processo. São propostas ousadas e que talvez não se encaixem em todos os cenários. São propostas que inclusive vão de encontro com o que costumamos classificar como boas práticas, porém foram abordagens que funcionaram dentro de seu contexto:
- Ser preguiçoso. Entender seus padrões de acesso e migrar primeiro os dados comumente acessados, se puder.
- Fazer ao vivo. Reunir o máximo de informações possível migrando ao vivo, identificando bugs antecipadamente e aprendendo a usar e executar a tecnologia.
- Testar em produção. Os dados em produção são sempre mais interessantes do que em ambientes de teste, portanto, introduzir verificações em produção onde puder.
A migração é sucesso absoluto. Desde a migração para o DynamoDB, o volume de usuários mensais da plataforma triplicou sem queda de performance. O banco de dados escala de acordo com as necessidades e com um custo menor do que o apresentado anteriormente com o uso dos clusters AWS RDS.
Entretanto, sacrifícios foram feitos em prol desses resultados: “alterações de schema e preenchimentos agora exigem escrever e testar rigorosamente o código de migração de varredura paralela, e perdemos a capacidade de executar consultas SQL ad-hoc em uma réplica do MySQL”. Mesmo assim, se essa migração fosse realizada hoje, o time ainda teria escolhido um dos novos SQL existentes no mercado, embora não necessariamente o DynamoDB, mas sim soluções como Spanner ou CockroachDB.

