

O novo coronavírus é um desafio de saúde pública como não se via desde o século passado e muitos foram aqueles que se posicionaram em todas as linhas para combater essa ameaça. Entre as muitas iniciativas, as universidades públicas brasileiras, a despeito de todas suas dificuldades estruturais, atenderam ao chamado do dever e estão contribuindo com essa luta.
A Universidade Federal Rural do Rio de Janeiro (UFRRJ) desenvolveu um laboratório virtual com o intuito de “potencializar a geração e circulação de conhecimentos relevantes ao enfrentamento da pandemia de COVID-19”. Dentro desse esforço coletivo, nasceu o projeto XRayCovid-19, uma plataforma de Inteligência Artificial que utiliza aprendizado de máquina para auxiliar o sistema de saúde no processo de diagnóstico.
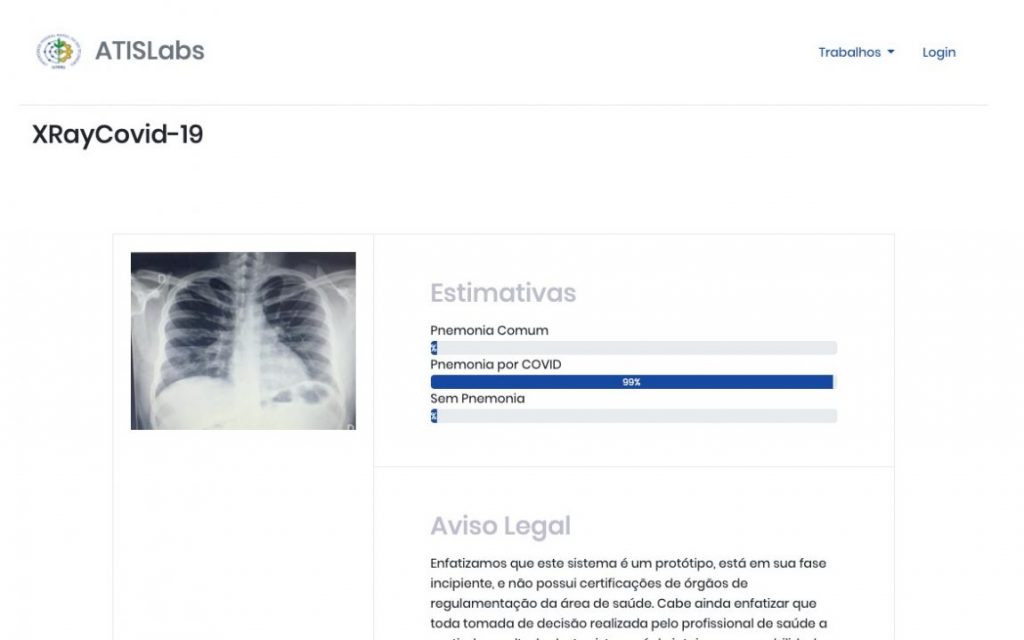
O aplicativo é resultado do trabalho dos professores Filipe Braida e Leandro Alvim, do Departamento de Ciência da Computação do Instituto Multidisciplinar, campus Nova Iguaçu, da UFRRJ. Com ele, a partir da avaliação de uma radiografia, o sistema verifica se a imagem possui o padrão associado à Covid-19, à pneumonia comum ou a nenhuma das duas. Entramos em contato com Leandro Alvim, para nos explicar melhor como foi projetado o XRayCovid-19 e quais tecnologias estão por trás do sistema.
1) O primeiro caso de coronavírus no Brasil foi registrado em 26 de fevereiro. Em menos de 2 meses, já temos um aplicativo com a capacidade do XRayCovid-19. Em quanto tempo foi desenvolvido o sistema e como vocês produzirão resultados tão rápidos?
O sistema inicial, com sua primeira versão de modelo e interface, que foi ao ar foi produzido em no máximo duas semanas.
O desenvolvimento foi rápido porque eu e Filipe temos mais de uma década de experiência com pesquisa em Aprendizado de Máquina e também sempre estivemos lecionando o conteúdo ou fazendo cursos extras. Desta forma, podemos dizer que não foi tão rápido assim.
2) Por que há tão poucos testes disponíveis no país e como o XRayCovid-19 se encaixa nesse cenário?
Ao meu ver, a curva de casos do Brasil é do passado, pois os testes tem um atraso de mais de uma semana para serem processados pelos laboratórios e, adicionalmente, existe um limite de kits. Também não sabemos por dia quantos testes são feitos, apenas os casos que deram positivo ou de óbito. Isto atrapalha ainda mais a análise. Desta forma, a curva não mede os casos e sim a natureza dos testes realizado no país.
Pensamos no XRayCovid-19 como um grande sistema integrado que operasse a baixo custo, que pudesse ser utilizado pelo celular, sem necessidade de instalação, e que desse um indicativo de diagnóstico rápido ao profissional de saúde ou mesmo facilitasse a triagem. Desta forma, poderia até mesmo complementar os kits, porém não substituir. Até porque nem todos os casos de manifestação da Covid-19 aparecem na radiografia. Nosso escopo é para os casos em que existe uma chace de manifestar. Manifestando, indicar a chance. Em conversas com radiologistas, foi importante saber que, para uma maior certeza, há a possibilidade futura de inserção de sintomas ou mesmo imagem de tomografia como padrão ouro. Entretanto, mesmo com a radiografia, a análise pelo ser humano especialista é muito difícil. Alguns não analisam ou mesmo erram.
3) Recentemente, o Google ganhou manchetes ao apresentar resultados muito precisos na detecção de câncer de mama com Inteligência Artificial. Como você vê o futuro desse recurso na Medicina Diagnóstica?
Vejo um futuro incrível para a medicina diagnóstica e acredito que temos o potencial de inovarmos com plataformas deste tipo no SUS. Vejo um futuro com estatísticas por região do país das doenças de forma a melhorar a gestão da saúde pública, bem como poder responder ou prever epidemias se os dados forem alimentados por uma IA moderna. Vejo também um amplo espaço para o crescimento da telemedicina, principalmente em comunidades remotas.
4) O XRayCovid-19 poderia ser classificado como um sistema de aprendizado de máquina ou aprendizado profundo? Houve uso de redes neurais no seu desenvolvimento?
É um sistema de aprendizado de máquina que utiliza redes profundas, as denominadas redes neurais convolucionais. Estas são o estado da arte para a classificação de imagens. Elas permitem uma boa generalização na classificação mesmo para uma entrada de dados rotacionada ou transladada, por exemplo.
5) Vocês optaram pelo uso de Julia no desenvolvimento do sistema. Esta tem sido a linguagem preferida de aplicações de Big Data. Poderia explicar a razão para essa decisão?
Julia é uma linguagem de alto nível, com uma sintaxe simples como a de Python, operações com matrizes embutidas como em Matlab e uma velocidade próxima da linguagem C ou Fortran. Julia chegou para resolver ” o problema das duas linguagens”. Não só isto, mas pode-se trabalhar com paralelismo de maneira bem simples.

Apesar de suas vantagens, ainda é uma linguagem em sua fase incipiente. Como consequência, necessita de uma maior comunidade e pacotes. Entretanto, vejo um futuro promissor para quem é da área. Eu e Filipe já trabalhamos com Julia faz tempo e temos pacotes oficiais da linguagem e orientamos um grupo de pesquisa em HPC com a linguagem por baixo.
6) Além de Julia, foi empregado o framework Flux. Como chegaram a essa escolha?
Foi um desafio, pois a comunidade é bem menor que a de Python com TensorFlow, Pytorch, MXNet e outros sabores. Entretanto é, ao meu ver, o framework mais elegante, com uma sintaxe pouco poluída e prazeroso até o momento para o desenvolvimento. Seu desempenho é similar aos demais tanto em tempo quanto em qualidade.
7) Qual é o tamanho do dataset utilizado para o algoritmo de detecção?
Já estamos com novas bases públicas e integrando. Desta forma, posso lhe informar que é na casa dos milhares para as categorias não covid.
8) O sistema é capaz de aprender a partir de radiografias enviadas pelos usuários? Como evitar distorções nos dados, nesse caso?
Sim, é. Bom, há diversas formas, desde uma arquitetura apropriada do tipo CNN que é mais resiliente às distorções e transformações na imagem a embutir um certo ruído na função de custo de forma a generalizar mais a rede. Há muita literatura à respeito disto e estamos avançando bem.

9) Qual é a acurácia atual do sistema? E o nível de especificidade?
Atingimos no primeiro modelo, uma acurácia média de 92% para as três classes. Entretanto, nossa base inicial carecia de mais exemplos e acreditamos que estamos num cenário atual de superestimativa. Entretanto, nosso próximo modelo utilizará uma base pelo menos cinco vezes maior. Resolvemos não detalhar aqui todas as métricas, porque em breve associaremos as versões do modelo a um relatório de qualidade no próprio site.
10) Quais são os próximos passos para o projeto nesse momento?
Desenvolvimento de um modelo de IA mais robusto com novas categorias de diagnóstico, bem como possibilidade de utilização de sintomas ou tomografias.

