


O Rust surgiu quase que por acaso. A linguagem de programação foi desenvolvida pela Mozilla Research, no ano de 2006. Nessa época, estava em desenvolvimento um projeto chamado “Mozilla Servo”, que tinha como objetivo de criar um novo mecanismo de renderização para o navegador Firefox. Com o tempo, percebeu-se a necessidade de uma linguagem de programação que pudesse oferecer um alto nível de segurança e desempenho, resultando no desenvolvimento da linguagem Rust. Curiosamente, o Servo nunca decolou, seu ciclo de desenvolvimento foi cancelado mais de uma vez, mas o Rust ganhou autonomia e escapou para novos horizontes.
Atualmente, Rust tem se destacado como uma das mais poderosas linguagens para o desenvolvimento de software confiável e eficiente. Hoje é possível encontrar o Rust em áreas como desenvolvimento de sistemas operacionais, aplicações de baixo nível, redes e blockchain. A linguagem encontrou lugar no kernel tanto do Linux quanto do Windows e ganhou defensores ferrenhos, que o apontam como o sucessor definitivo do veterano C e do C++.
Adam Chalmers é um desenvolvedor australiano que ajudou a construir partes do produto “Zero Trust” da Cloudflare, incluindo o Cloudflare Tunnel e o pacote Data Loss Prevention. Em um artigo publicado na internet, ele explica as vantagens de se adotar o Rust no backend, para projetos de alto nível.

Com sua autorização, traduzimos e reproduzimos o artigo na íntegra:
“Eu li e gostei do artigo de Andrew Israel, ‘I love building a startup in Rust. I wouldn’t pick it again‘ (nota da tradução: algo como ‘Eu amei montar uma startup em Rust. Eu não escolheria ele de novo’). Faz muito sentido! Ele basicamente diz que sua startup prioriza a produtividade do desenvolvedor em detrimento do desempenho. Escolha sensata para um fundador de startup fazer. Se o Rust vai atrasar seus desenvolvedores e você não precisa de seus benefícios, então você deve definitivamente considerar o uso de uma linguagem diferente.
Por outro lado, uso Rust como linguagem de alto nível na Cloudflare há alguns anos. Por ‘linguagem de alto nível’ quero dizer uma em que o desempenho realmente não importa muito. Tenho usado principalmente para servidores de API, onde a latência geral não importa muito. Eu ficaria totalmente bem usando uma linguagem com garbage collection ou uma linguagem interpretada, porque não preciso gastar cada microssegundo para um desempenho incrivelmente rápido. Eu só quero que meu servidor fique ativo, faça seu trabalho e deixe-me enviar recursos rapidamente.
Então, por que usar o Rust para uma tarefa como essa? Bem, embora Rust tenha a reputação de ser uma linguagem de sistemas de baixo nível, na verdade ela faz um trabalho admirável de agir como uma linguagem de alto nível. Portanto, aqui está minha lista de razões para considerar o uso do Rust, mesmo para um projeto em que o desempenho não é crítico.
1: Seus desenvolvedores já conhecem e gostam do Rust
Bem, este é fácil. Eu gosto do Rust (citação: veja o restante deste blog) e contratei desenvolvedores que gostam do Rust. Já somos bastante produtivos em Rust. Eu escolheria Rust em uma startup onde ninguém mais conhece Rust? Só se eu estivesse disposto a passar muito tempo orientando-os. Isso não se aplica! Queríamos escrever Rust e o fizemos, e isso nos deixou felizes.
Devo enfatizar: se ninguém mais em sua equipe conhece Rust, o custo de ensinar Rust a todos os seus colegas de trabalho será alto. Pode levar um tempo para que eles se tornem produtivos no Rust, e você precisará orientá-los e apoiá-los. Sua própria produtividade cairá durante isso. Sua posição padrão deve ser usar um idioma que o restante da equipe conheça, a menos que você realmente precise do Rust.
Felizmente para mim, meus colegas de equipe já conheciam Rust, gostavam de Rust e queriam se tornar melhores programadores de Rust, então isso não era uma preocupação.
2: Seu serviço interopera com serviços de desempenho crítico
Minha equipe criou o Data Loss Prevention para Cloudflare. O DLP basicamente executa ‘scans’ no tráfego que passa por alguma rede corporativa, para garantir que ninguém vaze dados privados, seja de forma maliciosa ou acidental. Por exemplo, ele pode detectar e bloquear um hacker carregando milhões de números de cartão de crédito de seu banco de dados para pastebin.org ou impedir que alguém envie por e-mail documentos do Microsoft Word com determinados rótulos do Office para e-mails do yahoo.com.
O serviço que realmente verifica o tráfego HTTP para evitar a perda de dados é chamado, imaginativamente, dlpscanner. Desde o início, sabíamos que o dlpscanner seria muito sensível ao desempenho, porque faz proxy de muitas solicitações HTTP, e não queremos que a navegação na Web dos usuários fique mais lenta quando eles ativam o DLP. Então, escrevemos isso em Rust. Tínhamos duas opções para a API de back-end: Rust ou Go. A decisão de usar Rust foi tomada considerando o que seria mais complicado: usar Rust no back-end ou adicionar uma segunda linguagem à nossa base de código.
Problemas de software
Quando começamos a planejar a API de back-end, sabíamos que ela teria que interoperar com o dlpscanner. Seria necessário compartilhar vários tipos, representando, por exemplo, configuração do usuário. O servidor de API serializaria a configuração do usuário em JSON, e o dlpscanner desserializaria esse JSON sempre que fosse necessário verificar uma solicitação.
Eu preferiria muito mais ter toda essa lógica de serialização e desserialização escrita em Rust, em vez de ter que definir meus modelos em dois idiomas e verificar se o idioma A pode desserializar qualquer idioma que B esteja serializando. Eu sei que há toda uma série de ferramentas como Captain Proto e Protocol Buffers para facilitar a interoperabilidade entre diferentes serviços, mas incluir esquemas de linguagem cruzada e as ligações de código geradas é muito irritante. Ou eu poderia apenas escrever algumas transformações JSON e testá-las cuidadosamente. Mas apenas escrever código Rust normal parecia muito mais simples.
Basicamente, gosto de poder compartilhar código entre diferentes partes do meu sistema. Usar Rust para serviços críticos de desempenho e serviços não sensíveis a desempenho simplifica muito a base de código geral.
Problemas de pessoas
É difícil alternar o contexto entre as linguagens de programação. Toda vez que volto para Go ou JS, levo algum tempo para me lembrar de que ‘ei, você precisa começar os nomes dos campos com letra maiúscula para torná-los públicos’ ou ‘ei, você precisa se lembrar de todas as diferentes pegadinhas para = =’. Aderir a um idioma facilita minha vida e minimiza o número de coisas novas que tenho para ensinar aos novos colegas de equipe.
3: Serde
Serde merece seu próprio marcador porque eu amo muito isso. Nos primeiros meses trabalhando com Go, escrevi muitos testes de unidade para de/serialização JSON porque a abordagem baseada em comentários do Go significava que, se eu cometesse um erro de digitação em algum lugar, o compilador não conseguiria detectá-lo. Por exemplo, no código Go abaixo:
type response struct {
PageCount int `json:"pageCount"`
FirstNames []string `json:"firstNames"`
}Os comentários estão anotando cada campo com qual deve ser sua chave JSON de/serializada. Isso é bom, mas é muito chato se você tiver muitos campos e precisar convertê-los manualmente para usar snake_case em vez de StandardGoFieldNameCase. E se você cometer um erro de digitação, oops, receberá um erro de tempo de execução. Ah, e é melhor você se lembrar de anotar todos os campos, porque o pacote JSON do Go só pode desserializar campos públicos (que começam com uma letra maiúscula), e o outro serviço provavelmente espera que os campos comecem com uma letra minúscula (snake_case ou camelCase) .
Em vez disso, em Serde, eu apenas escreveria:
#[serde(rename_all = "camelCase")]
struct Response {
page_count: i32,
first_names: Vec<String>,
}Isso gera um código sensato para de/serialização, sem a necessidade de testes de unidade. O Serde vem com muitos outros atributos prontos para ajudar a automatizar tarefas JSON. E sim, de/serializar JSON é um problema bastante central para qualquer back-end de API, então você deve tentar garantir que seja direto e não exija uma tonelada de lógica personalizada e testes de unidade.
Serde também é bom porque você pode começar apenas suportando JSON, mas é fácil adicionar suporte para outros padrões de serialização mais tarde. Se você acabar reutilizando esses tipos no código que é realmente sensível ao desempenho (veja acima), o serde pode lidar com uma tonelada de outros formatos de dados que são mais rápidos para desserializar.
Acabei de encontrar uma tonelada de bugs na minha de/serialização JSON em projetos anteriores, mas nunca tive um único problema desde que comecei a usar o Serde. Isso me salvou muito tempo. Se eu tivesse que escrever um novo projeto que dependesse fortemente da de/serialização de dados, eu tentaria usar Rust apenas para isso (ou JS, se eu soubesse que os dados seriam transportados apenas em JSON e que ambas as extremidades poderiam usar JS).
4: Bancos de dados
Rust não é incrível em bancos de dados, mas acho que é muito bom neles. Eu gosto muito de usar o Diesel porque ele gera todas as suas consultas SQL para você, a partir de um esquema SQL digitado que ele gera a partir das suas migrações SQL. Isso resolve alguns problemas:
- Quando você remove ou renomeia uma coluna em sua tabela SQL, como você verifica se todas as suas consultas existentes foram alteradas para entender o novo esquema?
- Se você modelar suas tabelas/linhas SQL em seu código e adicionar/alterar/remover uma coluna, como verificar se todos os seus tipos de código modelam com precisão seus tipos SQL? Isso é chamado de Dual Schema Problem. É muito chato manter seu esquema de código (JS, Go, Rust, qualquer que seja) e seu esquema SQL sincronizados.
Não gosto de mapeadores objeto-relacionais em todas as linguagens, mas o Diesel é muito bom porque agora, quando atualizo meu esquema SQL, o Diesel gera novamente os modelos Rust apropriados e quase todas as incompatibilidades entre meu código Rust e SQL agora se tornam erros de compilador que eu posso consertar.
Construir um modelo do sistema de tipo SQL dentro do sistema de tipo Rust é um trabalho impressionante. Também leva a problemas realmente irritantes, porque os tipos Diesel são muito complexos. Esses incluem:
- Mensagens de erro com mais de 60 linhas;
- Mensagens de erro que não fazem sentido (“este trait não foi implementado”, OK, claro, mas eu pensei que fosse, você poderia me dizer por que não foi? Não? OK, acho que vou chorar um pouco);
- Difícil de fatorar código comum em função compartilhada, porque duas consultas de aparência semelhante têm tipos totalmente diferentes.
Mas, no geral, se seu aplicativo depende muito do banco de dados para grande parte de sua funcionalidade, acho que vale a pena garantir que suas consultas de banco de dados sejam devidamente verificadas. As consultas de banco de dados não são um extra opcional em um back-end de API, elas são quase toda a sua base de código. Portanto, vale a pena verificar se estão corretos.
Sim, você pode simplesmente escrever todas as suas consultas SQL à mão e testá-las com muito cuidado, mas precisa pensar muito sobre seus testes de unidade, mantê-los sincronizados com o esquema de produção e garantir que não está propenso a SQL Injection porque você, não sei, fez um loop em uma matriz de ‘filtros’ e os mapeou para se tornarem cláusulas SQL WHERE. Diesel é um pé no saco às vezes, mas no geral acho que valeu a pena.
Entre Diesel e Serde, você pode gerar quase todo o código importante em sua API (ler solicitações, fazer consultas de banco de dados e escrever respostas), deixando mais tempo para escrever lógica de negócios, enviar recursos e focar na modelagem de seu domínio de negócios. Ah, falando nisso…
5: Melhor modelagem do domínio de negócios
É importante que uma API de back-end que armazena a configuração do usuário possa modelar corretamente o mundo real no software. Se o usuário estiver representando, digamos, o layout de seu escritório em seu software, seu sistema de tipos deverá ser capaz de modelar o escritório e não permitir que o usuário envie uma configuração inválida.
E, se possível, você deseja que essas configurações inválidas sejam detectadas no tempo de compilação em vez de no tempo de execução, para minimizar a quantidade de testes e códigos de verificação de erros necessários. Se uma determinada configuração não pode ocorrer no mundo real – por exemplo nenhum escritório do usuário pode estar localizado em dois fusos horários – então seu modelo de software não deve ser capaz de representar um escritório que tenha dois fusos horários. Essa ideia é chamada de ‘tornar os estados ilegais irrepresentáveis’. Há muitos artigos escritos sobre isso.
Rust tem dois recursos que realmente ajudam você a modelar seu domínio de negócios com precisão: enums e tipos não clonáveis.
Enums
Existe uma ideia muito interessante, chamada ‘sum types’ ou ‘uniões marcadas’ ou ‘tipos de dados algébricos’ ou ‘enums com valores associados’, dependendo da linguagem em que você está trabalhando. Adoro sum types. Eu os uso em meus projetos pessoais em Haskell, em Swift quando era um desenvolvedor de iPhone e em Rust na Cloudflare. Eles são realmente bons para modelar o domínio de negócios.
Enums permitem que você diga ‘Esta função retorna um erro ou uma estrutura Person. Não ambos. Nem nenhum. Exatamente uma dessas duas opções’. Quando não tenho enums, por exemplo em Go, preciso ler cuidadosamente cada função e verificar se a função que retorna (Pessoa, *err) pode retornar nenhum valor.
Eu gosto de modelar o domínio com enums. É ótimo dizer ‘este usuário pode iniciar meu software com um soquete TCP ou um soquete Unix’, e saber que o compilador verificará se você nunca passou acidentalmente por nenhum tipo de soquete, ou um terceiro tipo de soquete, ou alguma outra coisa .
‘Modelar com precisão o domínio de negócios’ é algo que me preocupa muito em APIs de alto nível. A correção é importante. Portanto, se eu realmente preciso garantir que meu modelo de software represente com precisão o mundo real, o Rust me oferece ferramentas melhores para fazer isso do que o Go.
Tipos não clonáveis
Alguns anos atrás, na Cloudflare, precisei modelar um conjunto de dez endereços IP. A ideia era que a rede de borda da Cloudflare tivesse dez IPs públicos e a cloudflared estivesse em execução no seu servidor e conectada a 4 desses 10 IPs para fins de balanceamento de carga.
Se um desses IPs estivesse ‘não íntegro’ e desconectado do cloudflared, o cloudflared deveria evitar reutilizá-lo e, em vez disso, usar algum IP que não tenha usado antes. Uma maneira natural de modelar isso é que cada IP tem três estados possíveis: em uso, não utilizado e usado anteriormente, mas agora não íntegro. Cada um desses IPs pode ser atribuído a uma das quatro conexões TCP de longa duração.
Parece um problema fácil de resolver, mas foi difícil modelar a ideia de que ‘cada endereço IP pode ser atribuído a no máximo uma conexão’. Tive que escrever muitos testes de unidade para encontrar casos extremos em que duas conexões diferentes tentariam pegar o mesmo endereço IP. Foi difícil porque em Go todos os valores podem ser copiados. Tentar garantir que haja apenas uma cópia de uma string específica, como ‘104.19.237.120’, requer muita disciplina do programador. As funções Go geralmente copiam valores ao redor ou copiam ponteiros para esse valor, por isso é difícil garantir que apenas uma goroutine esteja lendo seu valor.
Por outro lado, o Rust facilita a garantia de que determinados valores sejam “usados” apenas em um local. Só pode haver uma referência &mut a um valor a qualquer momento, portanto, certifique-se de que as funções que ‘usam’ o valor recebam um &mut para ele. Como alternativa, certifique-se de que seu tipo não implique Clone e certifique-se de que as funções que o ‘usam’ assumam a propriedade total do valor. O valor será movido para a função após o movimento, e a função pode ‘retornar’ o valor quando terminar.
Portanto, se eu quisesse implementar esse sistema em Rust, apenas manteria um HashSet dos meus dez endereços IP e garantiria que cada conexão levasse &mut para o IP que estava usando. Eu também me certificaria de que os IPs fossem um novo tipo UncloneableIp(std::net::IpAddr) e que eu não derivasse Clone para esse novo tipo.
Honestamente, isso não ocorre com muita frequência na prática – geralmente não há problema em copiar bytes na memória – mas, quando ocorre, é muito frustrante tentar auditar todas as funções e garantir que nenhuma delas esteja copiando um valor ou compartilhando referências a ele. Provavelmente, você pode simular isso com um RwLock (que, como o verificador de empréstimo do Rust, permite apenas que um thread tenha uma referência gravável para um valor), mas agora, se você errar, seu código trava, oops.
6: Confiabilidade
O desempenho pode não ser um problema para sua inicialização, mas a confiabilidade provavelmente é. Os clientes não gostam de pagar por serviços que ficam offline. Eu sei disso por experiência própria, já estive em ambos os lados dessa situação. Eu mantive alguns serviços realmente não confiáveis para novos produtos 😅
Evitando tiros no pé
Uma coisa boa sobre meus serviços de back-end do Rust é que eles basicamente nunca travam. Não há referências nulas que causem pânico instantâneo. Claro, há Option, e você sempre pode .unwrap() a opção que causará uma falha. Mas é muito fácil auditá-los na revisão de código, porque .unwrap() grita ‘Ei, preste atenção nisso, isso pode travar o programa’ de uma forma que apenas chamar .toString() em um objeto Javascript aparentemente normal não faria. Portanto, é muito fácil perceber na revisão do código. Na prática, o Rust geralmente tem maneiras melhores de lidar com as opções do que desembrulhá-las, então isso raramente surge durante as revisões de código da minha equipe. 95% dos desdobramentos em nossa base de código estão em testes de unidade.
Essa confiabilidade definitivamente vem com um pouco de sobrecarga do desenvolvedor, como pensar em como padronizar adequadamente todos os seus valores de Result e Option. Mas, para muitos domínios, essa compensação faz sentido. Nem todos eles. Acontece que trabalhei em muitos projetos em que cair era ruim e fico feliz em pensar com mais cuidado para evitar ser bipado no meio da noite.
Gestão de recursos
Rust não tende a usar muita memória ou vazar recursos (como conexões TCP ou descritores de arquivo) porque tudo é descartado e limpo quando uma função termina. Existem algumas exceções, como é possível ‘vazar tarefas’ como meus servidores Go vazam goroutines. Você deve certificar-se de usar os tempos limite apropriados em todos os lugares. @ThePrimeagen trabalha na Netflix e teve um tópico interessante no Twitter sobre o uso do Rust para um serviço de “alto nível”:
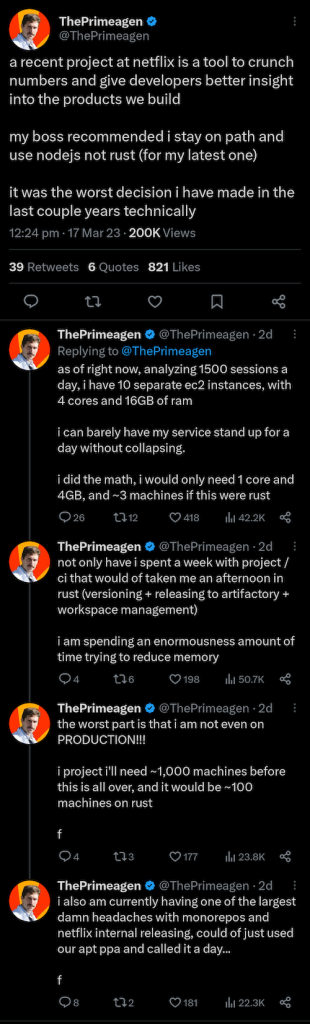
A lição que tirei disso é que, eventualmente, os problemas de desempenho se tornam problemas de confiabilidade. Se o seu serviço vazar memória por tempo suficiente ou ingerir dados suficientes, esse gargalo de desempenho pode derrubar seu serviço. Isso pode não se aplicar à sua situação. Mas se você acha que há uma chance de seu tráfego ou uso aumentar muitas ordens de magnitude em um dia – por exemplo, se um novo grande usuário se inscrever com vários OOMs maiores que seus clientes atuais – talvez valha a pena pensar nisso.
Conclusão
Acho que Rust pode fazer um trabalho admirável como uma linguagem de alto nível. Especialmente quando você está trabalhando em serviços da web, o Rust pode economizar seu tempo por meio de bibliotecas como serde e Diesel. O sistema de tipos torna a modelagem do seu domínio de negócios muito mais fácil. E seu serviço provavelmente não cairá com muita frequência.
Usar Rust para seus serviços da web ainda pode ser uma péssima ideia. Especialmente se sua equipe não tiver muita experiência em Rust. A curva de dificuldade do Rust é muito menor do que costumava ser, mas ainda é alta o suficiente para que você deva usar um idioma que sua equipe já conhece.
Na Cloudflare, a maioria de nossos serviços sensíveis a desempenho usa Rust, mas a maioria de nossos serviços de desempenho relaxado (como back-ends de API) usa Go. Minha equipe costumava usar Go para back-ends e migrou lentamente para Rust pelos motivos deste artigo. Essa compensação não faz sentido para todas as equipes, principalmente devido ao custo de aprender Rust e reescrever as principais bibliotecas de negócios em Rust (por exemplo, sua empresa pode já ter bibliotecas-chave que a maioria dos projetos integra para, por exemplo, modelar a configuração do usuário ou autenticar com um gateway de API ). Mas um número crescente de equipes está considerando o uso do Rust como back-end.
Novamente, minha heurística geral é usar qualquer linguagem que sua equipe já conheça para realizar o trabalho. Mas se sua equipe já conhece o Rust, definitivamente vale a pena considerá-lo para projetos de ‘alto nível’.”
Publicado originalmente como “Why use Rust on the backend?“, em 19 de março de 2023. Traduzido e republicado com autorização do autor.

