


O serviço de mensagens Discord foi lançado originalmente em maio de 2015. Apenas um ano e meio depois, já tinha atingido a impressionante marca de 25 milhões de usuários. Completando 8 anos agora, ele se tornou um ponto central de comunicações para 150 milhões de usuários ativos mensalmente, divididos em 19 milhões de salas de conversação, com cerca de 4 bilhões de minutos de conversas registradas diariamente e trilhões de mensagens.
Números impressionantes exigem soluções impressionantes no backend. Em 2017, o Discord adotou o banco de dados Cassandra, depois de ter iniciado suas operações com o MongoDB. A proposta daquela migração era utilizar uma solução que fosse escalável, tolerante a falhas e de manutenção relativamente baixa, uma vez que a plataforma estava crescendo de forma acelerada. Anos depois, o volume de mensagens foi multiplicado por mil. Foi então que Cassandra precisou ser substituído e uma nova migração começou.
Problemas com Cassandra
As mensagens do Discord estavam sendo armazenadas em um banco de dados chamado cassandra-messages. Em 2017, havia somente 12 nós Cassandra, o suficiente para se estocar bilhões de mensagens da plataforma. Porém, no início de 2022, o sistema tinha crescido para nada menos que 177 nós, com trilhões de mensagens. Os problemas começaram a aparecer, a latência havia se tornado imprevisível e o custo das operações de manutenção se tornaram muito elevados.
Da forma como estava estruturado, havia um outro problema: as leituras eram mais caras do que as gravações. As gravações eram anexadas a um log de confirmação e gravadas em uma estrutura na memória chamada memtable, que era posteriormente escrita no disco. As leituras, por outro lado, precisavam consultar a memtable e potencialmente vários SSTables (arquivos no disco), o que era um processo mais demorado. Muitas leituras simultâneas quando os usuários interagem com os servidores podiam sobrecarregar uma partição, que era chamada de “partição ativa”.
O que acontecia a seguir era uma reação em cascata: uma partição ativa geralmente afetava a latência em todo o cluster de banco de dados. Um determinado canal e balde recebiam uma quantidade significativa de tráfego, e a latência no nó aumentava à medida que ele lutava para acompanhar o tráfego. Isso também afetava outras consultas feitas a esse nó, pois ele não conseguia lidar com a demanda. Desta forma, todas as consultas aos nós que atendiam à partição ativa sofriam um aumento na latência, resultando em um impacto maior para o usuário final.
Até mesmo tarefas de manutenção no cluster também davam dores de cabeça aos administradores. Muitas vezes, havia atrasos nas compactações, quando o Cassandra combinava as SSTables no disco para melhorar o desempenho das leituras. Isso não apenas tornava as leituras mais lentas, mas também causava outra cascata, quando um nó tentava realizar a compactação.
O problema se multiplicava a partir do momento em que o cluster de mensagens não era o único banco de dados em Cassandra dentro do Discord. Existiam vários outros clusters e todos apresentavam falhas similares.
Uma nova arquitetura
Os administradores consideraram o ScyllaDB, um banco de dados compatível com o Cassandra escrito em C++, como uma alternativa viável. Eles já haviam explorado essa solução durante a migração do MongoDB para o Cassandra, mas agora estavam mais dispostos a considerar o ScyllaDB devido ao seu potencial de melhor desempenho, reparos mais rápidos, isolamento robusto da carga de trabalho e outras vantagens.
Uma das vantagens notáveis do ScyllaDB era a ausência de coletor de lixo, uma vez que era escrito em C++ em vez de Java. A equipe do Discord estava enfrentando várias dificuldades com o coletor de lixo do Cassandra, desde pausas que impactavam a latência até longas pausas consecutivas. Em alguns casos, a situação chegou ao ponto em que um operador precisava reiniciar manualmente um nó específico e monitorá-lo até que se recuperasse.
Após experimentar o ScyllaDB e observar melhorias, foi decidido migrar todos os bancos de dados do Discord. Até 2020, todos os bancos de dados, exceto um, foram migrados para o ScyllaDB. O único banco de dados restante era justamente o cassandra-messages, que era imenso, com trilhões de mensagens e quase 200 nós.
Antes de enfrentar o desafio de migrar esse banco de dados, a equipe de administradores decidiu familiarizar-se com o ScyllaDB em ambiente de produção, trabalhando com os outros bancos de dados, a fim de entender suas limitações e benefícios. Além disso, eles se empenharam em aprimorar o desempenho do ScyllaDB para outros casos de uso do Discord.
Durante os testes, foi constatado que o desempenho das consultas reversas não atendia às necessidades da plataforma. A equipe do ScyllaDB priorizou melhorias e implementou consultas reversas eficientes, eliminando o último obstáculo para a migração do banco de dados.
Entra em ação o Rust
Um dos problemas na implementação do Cassandra, eram as chamadas partições quentes, em que o alto tráfego direcionado a uma determinada partição resultava em simultaneidade descontrolada, levando a um aumento progressivo na latência das consultas. Foi necessário então desenvolver serviços intermediários de dados, que atuariam entre o monólito de API e os clusters de banco de dados. É nesse ponto que entrou a linguagem de programação Rust para escrever esses serviços. Os desenvolvedores desejavam aproveitar sua velocidade (comparável ao C/C+)+ e seu foco na segurança.
Outra vantagem fundamental da linguagem é que o Rust oferece suporte nativo à concorrência, o que facilita a escrita de código concorrente seguro. O ecossistema Rust, em particular a biblioteca Tokio, serve como uma base sólida para o desenvolvimento de sistemas assíncronos de E/S. Além disso, o Rust possui suporte de driver para os bancos de dados Cassandra e ScyllaDB.
Fluxo de dados
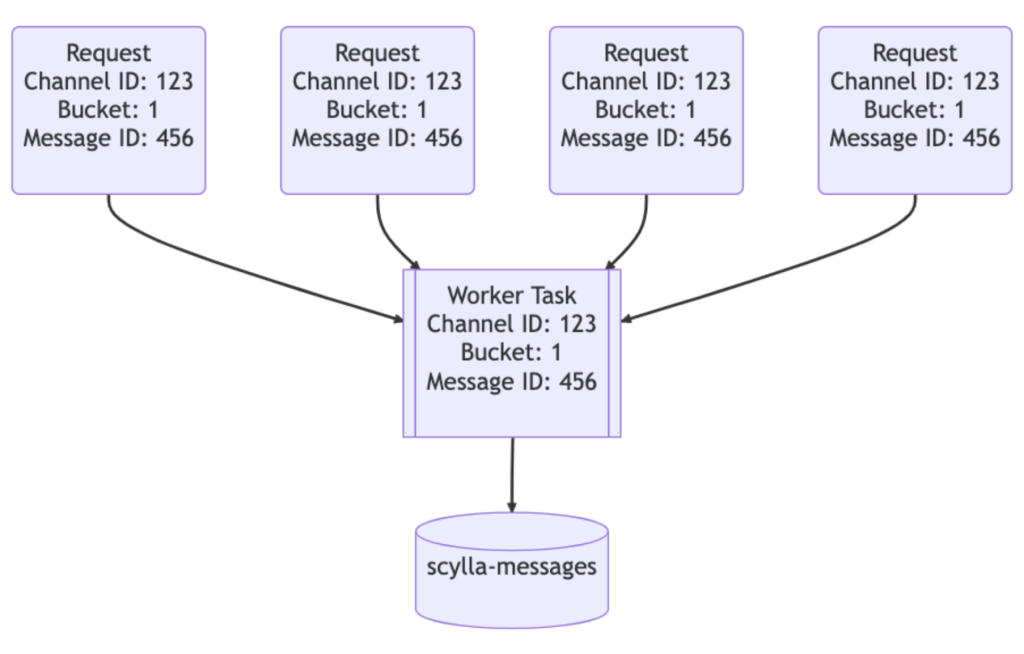
Para otimizar ainda mais o desempenho, a equipe do Discord construiu um roteamento baseado em hash consistente nos serviços de dados. Cada solicitação foi associada a uma chave de roteamento, como um ID de canal para mensagens. Dessa forma, todas as solicitações para o mesmo canal passaram a ser direcionadas para a mesma instância do serviço de dados, reduzindo a carga no banco de dados.
Embora essas melhorias tenham contribuído para a redução dos problemas de partições quentes e latência no cluster Cassandra, os problemas não foram extintos, apenas se tornaram menos recorrentes. O objetivo final era era realmente mover o cluster para o ScyllaDB ideal e completar a migração de dados.
Um desafio significativo
Os requisitos para a migração eram complexos: trilhões de mensagens precisavam ser migradas sem interrupções e com rapidez. Era necessário realizar todo o processo em etapas muito bem coordenadas, para evitar transtornos.
A primeira etapa consistiu em provisionar um novo cluster ScyllaDB utilizando uma topologia de armazenamento de superdisco. Essa configuração aproveitava a velocidade dos SSDs locais e a durabilidade do disco permanente ao utilizar RAID para espelhar os dados. Com o novo cluster operacional, foi possível iniciar a migração dos dados.
O plano de migração inicial foi projetado para trazer benefícios rapidamente. A ideia era começar a utilizar o novo cluster ScyllaDB para os dados mais recentes, utilizando um ponto de corte, e, em seguida, migrar os dados históricos posteriormente. Embora isso introduzisse mais complexidade, acreditava-se que valeria a pena.
Foi iniciada a gravação duplicada dos novos dados tanto no Cassandra quanto no ScyllaDB, ao mesmo tempo em que o migrador Spark do ScyllaDB estava sendo provisionado. Essa etapa exigiu diversos ajustes e, uma vez configurada, estimou-se um prazo de três meses para conclusão.
No entanto, a equipe decidiu buscar maneiras de acelerar o processo. Lembraram-se de ter desenvolvido uma biblioteca de banco de dados rápida e de alto desempenho, que poderia ser estendida. Assim, optaram por reescrever o próprio migrador de dados em Rust.
Em uma tarde, a biblioteca de serviços de dados foi estendida para suportar migrações de dados em larga escala. Essa extensão lia intervalos de token de um banco de dados, verificava-os localmente usando o SQLite e, em seguida, os enviava para o ScyllaDB. Com o migrador aprimorado em funcionamento, uma nova estimativa foi obtida: apenas nove dias! Com a possibilidade de migrar os dados rapidamente, decidiu-se abandonar a abordagem complicada baseada em lotes e realizar a migração completa de uma vez.
Para validar os dados, foi realizado um teste automatizado enviando uma pequena porcentagem de leituras para ambos os bancos de dados e comparando os resultados. Tudo parecia estar funcionando corretamente. Enquanto o cluster resistia bem ao tráfego de produção, o Cassandra continuava sofrendo com problemas frequentes de latência. Então, a equipe simplesmente decidiu tornar o ScyllaDB o único banco de dados. Em maio de 2022, a migração havia sido completada com êxito
Um ano depois…
O que antes exigia 177 nós em Cassandra agora pode ser executado em 72 nós no ScyllaDB. Isso é possível porque cada nó ScyllaDB possui 9 TB de espaço em disco, superando a média de 4 TB por nó do Cassandra.
As latências também melhoraram significativamente. Por exemplo, a busca por mensagens históricas tinha um p99 entre 40-125ms no Cassandra, enquanto no ScyllaDB apresenta uma latência suave de 15ms p99. O desempenho de inserção de mensagens, que variava entre 5-70ms p99 no Cassandra, agora é consistente em 5ms p99 no ScyllaDB. Graças a essas melhorias de desempenho, eles descobriram novos casos de uso para seus produtos, agora que existe a confiança em seu banco de dados de mensagens.
A prova de fogo para a nova arquitetura aconteceu no final de 2022, quando usuários ao redor do mundo todo estavam sintonizados para assistir à Copa do Mundo. O evento esportivo repercutiu na plataforma, com picos de mensagens a cada gol marcado. A prova definitiva da resiliência e da velocidade do ScyllaDB no Discord aconteceu na final histórica da competição. Enquanto torcedores em escala global estavam estressados assistindo a uma partida que foi marcada por momentos extraordinários, o Discord e o banco de dados de mensagens estavam serenos. O envio de mensagens em níveis jamais vistos na plataforma estava avançado e sendo tratado perfeitamente.
A migração foi um sucesso inequívoco e sobreviveu à provação: com seus serviços de dados agora baseados em Rust e ScyllaDB, o Discord conseguiu lidar com esse tráfego e fornecer uma plataforma para que seus usuários se comunicassem.

